

大家好,我是元壤教育的张涛,一名知识博主,专注于生成式人工智能(AIGC)各领域的研究与实践。我喜欢用简单的方法,帮助大家轻松掌握AIGC应用技术。我的愿景是通过我的文章和教程,帮助1000万人学好AIGC,用好AIGC。
小伙伴们!这一章咱们要聊聊如何在提示词工程中监控提示词的有效性。这个任务非常关键,因为我们得确保像ChatGPT这样的语言模型能够生成准确且上下文相关的回应。
通过实施有效的监控技术,我们可以发现潜在问题,评估提示词效果,并改进提示词,以提升整体用户互动体验。好,话不多说,咱们开始吧!
定义评估指标
-
任务特定指标:定义任务特定的评估指标至关重要,因为这些指标能衡量提示词在实现每个特定任务的预期结果方面的表现。比如,在情感分析任务中,准确性、精确度、召回率和是常用的指标。
好的,那咱们用大白话来解释F1分数。
F1分数是用来评价一个分类模型好不好的指标。它结合了准确率和召回率,找到了一个中间的平衡点。
几个关键概念:
准确率(Precision):在模型预测的所有“正例”中,真正是“正例”的比例。
举个例子,假设你的模型说有10个人有病,但实际上只有8个人真有病,那准确率就是8/10,也就是80%。
召回率(Recall):在所有实际的“正例”中,模型正确识别出的比例。
还是刚才的例子,如果实际有10个人有病,模型正确地识别了其中的8个人,那召回率就是8/10,也就是80%。
F1分数是怎么来的?
F1分数把准确率和召回率结合起来,通过一个公式来计算:
你可以把它想象成一个折中的评分,既考虑到你有多精确(准确率),又考虑到你有多全面(召回率)。
简单比喻:
假设你在抓小偷:
准确率:你抓的这些人里,有多少真的是小偷。比如你抓了10个人,8个真是小偷,那准确率是80%。
召回率:所有小偷里,你抓到了多少。比如实际有10个小偷,你抓到了8个,那召回率是80%。
F1分数就是综合了这两个比例,看你总体表现如何。
一个实际例子:
如果你的模型在100个样本中:
预测了20个人有病(正例),其中18个真有病(准确率90%)
实际有20个人有病,你预测对了18个(召回率90%)
那么,F1分数就是:
总结
F1分数帮你看模型在“抓小偷”这件事上,既抓对了多少,又漏掉了多少,是一个综合性的评价指标。
希望这个解释能让你更容易理解F1分数!
PS:来自ChatGPT的解释


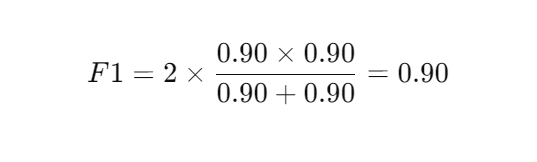
-
语言流畅性和连贯性:除了任务特定的指标,语言的流畅性和连贯性也是提示词评估的关键。可以用BLEU和ROUGE等指标,把模型生成的文本和人类写的参考文本进行比较,从而了解模型生成连贯且流畅回应的能力。
BLEU: 当评估机器翻译或生成文本的质量时,我们需要一种方法来衡量机器生成的文本与人类翻译或参考文本之间的相似程度。这就是BLEU(Bilingual Evaluation Understudy)的作用。BLEU通过比较生成的文本与参考文本的词汇和短语匹配情况来评估文本的质量。
具体来说,BLEU首先将文本转换成n-gram(连续的n个词或字符)序列,然后计算生成文本中的n-gram在参考文本中出现的频率。
最后,BLEU根据匹配的n-gram数量以及生成文本的长度来计算一个得分,得分越高表示生成的文本质量越好。BLEU的优点是简单易用,而且能够快速评估生成文本的质量。它被广泛应用于机器翻译和自然语言生成等领域,是一种常用的评估指标。
ROUGE:ROUGE是一种用来评价自动生成的摘要与参考摘要之间相似度的方法。它看生成的摘要中有多少词和参考摘要相同。ROUGE主要考虑的是自动生成的摘要是否包含了参考摘要中的关键信息,也就是我们常说的“召回率”。
ROUGE有几种不同的版本,比如ROUGE-N,它主要看的是生成的摘要和参考摘要中的连续词组有多少是一样的。而ROUGE-L则是看两者中最长的相同子序列有多长。ROUGE的这些版本可以根据不同任务和需求来选择使用。
总的来说,ROUGE帮助我们判断自动生成的摘要和人工写的摘要之间的相似程度,从而评价自动摘要的质量。
人工评估
-
专家评估:请熟悉特定任务的领域专家来评估模型输出。他们能提供宝贵的定性反馈,评估模型响应的相关性、准确性和上下文性,并识别潜在的问题或偏见。
-
用户研究:通过用户研究,收集真实用户与模型互动后的反馈。这种方法能提供关于用户满意度、改进领域和整体用户体验的宝贵见解。
自动评估
-
自动指标:自动评估指标补充了人工评估,提供提示词有效性的定量评估。常用的指标包括准确性、精确度、召回率和F1得分。
-
与基线比较:将模型的响应与基线模型或黄金标准参考进行比较,可以量化提示词工程取得的改进效果。这有助于理解提示词优化工作的成果。
上下文和连续性
-
上下文保持:对于多轮对话任务,监控上下文保持非常重要。这涉及评估模型是否考虑了之前互动的上下文,以提供相关且连贯的回应。上下文保持良好的模型能带来更流畅和吸引人的用户体验。
-
长期行为:评估模型的长期行为,看看它能否记住并整合之前互动中的相关上下文。这种能力在持续对话中尤为重要,以确保一致且上下文适当的响应。
适应用户反馈
-
用户反馈分析:分析用户反馈是提示词工程的重要资源。它帮助提示词工程师识别模型响应和提示词设计中的模式或反复出现的问题。
-
迭代改进:根据用户反馈和评估结果,提示词工程师可以不断更新提示词,以解决痛点并增强整体提示词性能。这种迭代方法有助于模型输出的持续改进。
偏见和道德考虑
-
偏见检测:提示词工程应包括检测模型响应和提示词表述中潜在偏见的措施。实施偏见检测方法有助于确保语言模型输出的公平性和无偏见性。
-
偏见缓解:解决和缓解偏见是创建伦理和包容性语言模型的关键步骤。提示词工程师必须在设计提示词和模型时考虑公平性和包容性。
持续监控策略
-
实时监控:实时监控能让提示词工程师及时发现问题并提供即时反馈。这种策略确保提示词得到优化,提升模型的响应能力。
-
定期评估周期:设立定期评估周期,使提示词工程师能够跟踪提示词性能随时间的变化。这样可以衡量提示词变化的影响,并评估提示词工程工作的有效性。
即时评估的最佳实践
-
任务相关性:确保评估指标与提示词工程项目的具体任务和目标相匹配,对于有效的提示词评估非常重要。
-
指标平衡:采用结合自动化指标、人工评估和用户反馈的平衡方法,提供关于提示词有效性的全面见解。
用例和应用
-
客户支持聊天机器人:监控客户支持聊天机器人的提示词有效性,确保对用户查询的响应准确且有帮助,从而提升客户体验。
-
创意写作:在创意写作任务中,提示词评估有助于生成上下文适当且引人入胜的故事或诗歌,增强语言模型的创作输出。
结论
本章中,我们探讨了在提示词工程中监控提示词有效性的意义。定义评估指标、进行人工和自动化评估、考虑上下文和连续性以及适应用户反馈是提示词评估的关键方面。
通过持续监控提示词并采用最佳实践,我们可以优化与语言模型的互动,使其在各种应用中成为更可靠和有价值的工具。有效的提示词监控有助于不断改进像ChatGPT这样的语言模型,确保它们满足用户需求,并在不同背景下提供高质量的响应。
好了,今天的内容就到这里啦,希望大家能从中受益,继续加油哦!
写在最后
-
元壤教育为3000万大学生和职场人士提供免费的AIGC课程培训。如果你希望系统地免费学习AIGC提示词工程、图像创作、音频创作、音乐创作、短视频创作以及AIGC+办公等内容,请关注公众号,开启你的免费学习之旅。
-
如果你想系统、沉浸式地从0到1学习更多AIGC应用内容,请获取更全面的AIGC内容。
其他内容:

{kind=link}